Neural networks, zwarte dozen en vooroordelen
01-03-2022
De keerzijde van neutral networks
Neural networks – een vorm van machine learning – bootsen het menselijke brein met zijn vele neuronen na. Ze zijn in staat patronen te herkennen in enorme hoeveelheden data waar wij die in geen duizend jaar zouden zien (althans, deze auteur/wiskundeneanderthaler zeker niet). Dat heeft ervoor gezorgd dat neural networks sinds 2012 aan een grote opmars bezig zijn.
Deze neural networks – en Artifical Intelligence (AI) in het algemeen – bieden grote mogelijkheden voor organisaties. AI is een containerbegrip voor allerlei systemen of machines die (complexe) taken uitvoeren op een wijze die lijkt op intelligent menselijk gedrag. Toch kunnen ze ook een keerzijde hebben. AI-systemen kunnen biased zijn door verkeerde of inferieure trainingsdata, bewust of onbewust de vooroordelen van de programmeur bevatten en/of ondoorzichtig tot besluiten komen. Daarom is het van belang dat maatregelen worden genomen om deze problemen zoveel mogelijk te beperken of zelfs te elimineren. In deze blog lees je hoe je dat doet.
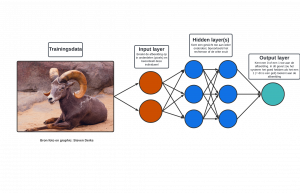
Hoe werkt het?
In principe bestaan neural networks uit drie onderdelen – of lagen van nodes (neuronen):
- Een input layer waar je training data in stopt;
- Een of meerdere verborgen lagen (of hidden layers) die een bepaald gewicht aan data toekennen;
- Een output layer.
Een voorbeeld: de trainingsdata kan een foto van een geit zijn die in de input layer wordt opgedeeld in onderdelen of pixels. Vervolgens kennen hidden layers een gewicht toe aan de pixels van die foto en wordt uiteindelijk in de output layer een 0 of 1 toegekend. Is de waarde 1, dan heeft het systeem correct gedetecteerd dat een geit is afgebeeld op de foto.
Black box
Aangezien ik ’s nachts nog regelmatig in angstzweet uitbreek bij flashbacks naar wiskundelessen van vroeger, is bovenstaande tekst uiteraard een zeer simplistische weergave van een neural network. In werkelijkheid gaan er uiterst complexe berekeningen en modellen schuil achter de schermen. Deze complexiteit heeft ervoor gezorgd dat (de meeste) neural networks het karakter van een black box hebben gekregen. Ja, de berekeningen, nodes en weights zijn bekend bij een neural network. Toch zegt dat weinig tot niets over hoe het systeem tot een bepaalde uitkomst is gekomen.
Via internet kwam ik ooit de volgende uitleg tegen: “Je kan een hersenscan van iemand uit laten voeren; je vraagt die persoon om een artikel te schrijven over honden. Het maakt niet uit wat, als het maar over honden gaat. Via de hersenscan (ervan uitgaande dat het een real-time scan is) kun je zien welke neuronen worden afgevuurd. Ook neem je waar dat iemands verbeelding erop losslaat, de persoon is immers aan het schrijven en de pen glijdt over het papier. Tijdens deze opdracht weet je wat ieder deel van de hersenen van de schrijver doet, wat de samenhang is tussen die delen en wat het nut is van ieder deel. Toch weet je niet wat de schrijver denkt.”
Oftewel, je kan het resultaat waarnemen van het gedachteproces, maar niet hoe de schrijver heeft besloten die specifieke gedachte uiteindelijk op te schrijven. Je hebt niets gezien van de vele gedachten die door het hoofd van de schrijver gingen voordat hij een bepaalde zin op papier zet. Dat is in de kern het probleem van een black box.
Een stap in de goede richting
Recentelijk las ik een artikel over een veelbelovende stap in de goede richting (Scitechdaily, 2022) Onderzoekers van het Massachusetts Institute of Technology (MIT) hebben een nieuwe methode ontwikkeld waarbij automatisch wordt beschreven wat individuele onderdelen van een neural network doen. Deze beschrijving wordt gedaan in natural language, de voor mensen begrijpelijke taal. In het voorbeeld van de foto van de geit, kan een label worden gehangen aan een node die de rechterhoorn van een bruine dwerggeit herkent.
Wat wellicht nog belangrijker is, is de claim van de MIT-onderzoekers dat ze neural networks kunnen auditen op wat het heeft geleerd. Ze zouden met hun methode zelfs incorrecte of nutteloze nodes kunnen uitschakelen. Hoewel er al technieken bestaan die helpen te begrijpen hoe een model werkt, zijn deze nog ruw of vergen ze veel tijd.
Deze nieuwe methode is uniek omdat het geen lijst met concepten vooraf nodig heeft en automatisch beschrijvingen in natuurlijke taal kan genereren voor alle neuronen in het model. Dat is met name van belang omdat een enkel neural network wel honderdduizenden neuronen kan bevatten. Deze methode kan, te zijner tijd, bijdragen aan het reduceren (elimineren is vaak onmogelijk) van onwenselijke bias.
Bias en het ‘neutrale’ algoritme
Bias, dat zoiets als vooroordeel of vooringenomenheid in het Nederlands betekent, is een veelgehoorde term in de wereld van Artificial Intelligence. Simpel gezegd is bias het fenomeen waarbij er een vooroordeel bestaat over bijvoorbeeld een persoon, een groep of idee. Logischerwijs zijn termen als discriminatie, ongelijke behandeling en voorkeursbehandeling verwant aan bias. Alhoewel menig mens deze verschijnselen probeert te voorkomen, zijn we ons vaak niet bewust van onze bias. Er wordt nog weleens gedacht dat bias iets is dat enkel voorkomt in een sociale of politieke context. Daartegenover zou staan dat een algoritme volledig vrij is van enige bias, het is immers een ‘neutraal’ computerprogramma. Toch is het tegendeel waar.
Bias in trainingsdata
Ten eerste is een algoritme volledig afhankelijk van de data die het wordt gevoed. Als deze data niet evenwichtig is, heb je al snel te maken met data waar bias inherent aan is. Een bekend voorbeeld hiervan is Amazon die een AI ontwikkelde om de selectieprocedure voor cv’s te automatiseren. Al snel bleek dat het algoritme de voorkeur gaf aan cv’s van mannen (Siliconrepublic, 2018).
Dit kwam doordat de modellen van Amazon zijn getraind met cv’s van sollicitanten die over een periode van 10 jaar aangenomen waren. Aangezien de Techsector traditioneel oververtegenwoordigd wordt door mannen, leerde het algoritme dat mannen vaak worden aangenomen, dus het zijn van een man betekent dat je goed bent, dus mannen zijn beter dan vrouwen. Overigens is hier een bijzonder feit dat gender helemaal geen criterium was dat aan de AI werd meegegeven. Echter, door bovenstaande redenering naar aanleiding van de trainingsdata, ontwikkelde het systeem zelf het criterium waarbij cv’s van mannen de voorkeur kregen. Vanzelfsprekend werd de AI van Amazon snel uitgeschakeld nadat het bedrijf zich realiseerde dat het nieuwe systeem kandidaten voor banen voor softwareontwikkelaars en andere technische functies niet op een genderneutrale manier beoordeelde.
Een ander veelvoorkomend voorbeeld is gezichtsherkenningssoftware die personen met een donkere huidskleur niet herkent. Dat komt doordat de trainingsdata veelal foto’s van personen met een lichtere huidskleur bevat. Daardoor leert het systeem onderscheid te maken tussen personen met een lichtere huidskleur, maar worden personen met een donkere huidskleur niet snel individueel herkend. Dit is een probleem dat doorgaans opgelost kan worden door de trainingsdata te diversifiëren. Toch zijn er ook vormen van bias die een hardnekkiger probleem vormen. Bij deze soorten krijgen we te maken met de eerder besproken black box.
Bias in het algoritme en de black box
Banken werken regelmatig met risico-indicaties om de kredietwaardigheid van klanten te beoordelen. Zo kunnen personen die in categorie X vallen minder geld lenen dan personen die in categorie Y vallen. Wanneer deze classificatie bijvoorbeeld door een neural network wordt gedaan, omdat deze enorme hoeveelheden data kan verwerken en daar patronen in kan zien, volgt er een resultaat als output waarbij de ene persoon in groep X komt en de andere persoon in groep Y.
Dat is geen probleem als precies kan worden aangetoond hoe het systeem tot dit resultaat is gekomen. Echter, omdat het een black box is, is dat niet altijd vast te stellen. Zo kan het zomaar zijn dat het systeem een bias heeft ontwikkeld voor het verlagen van kredietwaardigheid van personen woonachtig in achterstandswijken. Zoals menig onderzoek heeft aangetoond, zegt een voorspelling over een groep niets over een specifiek individu. Desondanks kan een klant van de bank dan worden benadeeld door het loutere feit dat zijn postcode in een bepaald gebied valt. Dat is een vorm van bias die niet direct zichtbaar is doordat deze schuilgaat in de mysterieuze black box (het recht om niet onderworpen te worden aan automatische besluitvorming zonder menselijke tussenkomst, verankerd in art. 22 van de AVG, is voor de informatieve aard van deze blog niet relevant).
Bias van de programmeur
Tot slot kan een algoritme de (veelal onbewuste) bias van een programmeur bevatten. Deze vorm van bias is een vreemde eend in de bijt, omdat het hier niet gaat om technische, maar om menselijke bias. Dit soort bias wordt in de psychologie ook wel impliciete bias genoemd.
Bij impliciete bias gaat het om vooroordelen waar we ons niet bewust van zijn. Dat kan zich bijvoorbeeld uiten in het stereotypering. Bij stereotypering kennen mensen zekere kwaliteiten of eigenschappen toe aan alle leden van een bepaalde groep. Zelfs wanneer je dat niet bewust doet, kan ieder mens dit overkomen. Aangezien een programmeur het algoritme programmeert dat de AI laat werken, komt het regelmatig voor dat diegene ook onbewust bias in het algoritme verwerkt.
Denk bijvoorbeeld aan de toeslagenaffaire. Alhoewel de situatie daar iets genuanceerder ligt, zorgde impliciete bias van meerdere (verantwoordelijken van) programmeurs voor uiterst negatieve consequenties voor betrokkenen. Het zou zomaar kunnen zijn dat die programmeurs onbewust een dubbele nationaliteit met fraudeurs associëren, waardoor ze niet voldoende waarborgen troffen om die bias te mitigeren.
Uit bovenstaande voorbeelden blijkt dat AI verre van neutraal is, zoals vaak wordt gedacht. Dat kan dus komen door biasedtrainings- of inputdata, door de (onbewuste) vooroordelen van de programmeur die worden weerspiegeld in het algoritme of doordat de AI gaandeweg zelf een bias ontwikkelt.
Van zwarte naar glazen dozen
Nu de problematiek van de black box en de bias in AI is uitgelegd, is het tijd om een blik te werpen op twee mogelijke oplossingen.
Ethics by design
Ethics by design is een principe dat menig privacy professional doet denken aan privacy by design uit art. 25 van de AVG. Dat is niet gek, aangezien ze dezelfde onderliggende gedachte hebben: ethiek/privacy een integraal onderdeel uit laten maken van je algoritme/gegevensverwerking.
Een interessant detail is dat de Europese Commissie (EC) privacy als een onderdeel noemt van ethics by design. Dat is te lezen in een niet-bindende richtlijn die de High-Level Expert Group on AI namens de EC heeft opgesteld. Deze richtlijn bevat heldere principes die in iedere AI verwerkt zouden moeten zijn. Niet alleen vanuit ethisch oogpunt, maar ook omdat het reputatieschade, tijd en kosten achteraf kan besparen indien een AI bijvoorbeeld blijkt te discrimineren. Daarnaast zorg je voor meer vertrouwen van je klanten wanneer je transparant bent over de werking van de AI die je toepast
Kwaliteit van trainingsdata en antibiasstrategieën
Wanneer je als organisatie AI gebruikt, is het van belang dat je je trainingsdata controleert. Zo dient de trainingsdata voldoende divers en groot genoeg te zijn om de meest voorkomende vormen van bias te voorkomen. Bijvoorbeeld of een bepaalde bevolkingsgroep oververtegenwoordigd is of dat een bepaalde eigenschap weinig voorkomt.
Daarnaast is het van belang dat een integrale antibiasstrategie wordt opgericht. Daarbij kunnen allerlei maatregelen worden getroffen om bias te beperken en, waar mogelijk, zelfs te elimineren. Denk bijvoorbeeld aan technische maatregelen zoals de eerdergenoemde methode van de MIT-onderzoekers. Dat is een methode om de beruchte zwarte dozen om te toveren tot glazen dozen, waardoor verborgen bias kan worden opgespoord en gemitigeerd.
Idealiter zorg je bij de ontwikkeling van de AI al voor dat alle toekomstige beslissingen uitlegbaar en transparant zijn. Hierdoor wordt de kans op een black box aanzienlijk verkleind of verdwijnt deze zelfs volledig. Ook kan worden gedacht aan het diversifiëren van het personeel bij de ontwikkeling en (periodieke) controle van de AI. Vaak zijn we ons niet bewust van onze vooroordelen, waardoor een frisse blik van een collega soms veel kan schelen.
In dit artikel ging het voornamelijk over neural networks, een veelvoorkomende soort of subcategorie van AI. Ondanks dat deze oplossingen zijn toegespitst op neural networks, zijn ze over het algemeen ook relevant voor veel andere AI-systemen.
Conclusie
Neural networks bieden grote mogelijkheden voor organisaties. Zo kunnen ze patronen herkennen in enorme hoeveelheden dat en bepaalde werkzaamheden (volledig) automatiseren. Toch kleven er ook nadelen aan neural networks en AI in het algemeen.
Wanneer je je als organisatie bewust bent van deze nadelen, kan je stappen nemen om ze te mitigeren. Dat kan door ethiek al bij de ontwerpfase van een AI in acht te nemen en waarborgen in het systeem te bouwen. Daarnaast is het van belang om ook na de ontwikkeling periodieke controles uit te voeren op het systeem. Hiermee worden onwenselijke effecten van het systeem gelokaliseerd en gemitigeerd.
Tot slot is een integrale antibiasstrategie raadzaam. In zo een strategie komen de eerdergenoemde – en andere – maatregelen gezamenlijk aan bod. Door al deze maatregelen een kern van je AI-gerelateerde activiteiten te maken, kun je verantwoord innoveren en AI inzetten om je organisatie naar een hoger niveau te tillen.
Hulp nodig?
Heb je vragen over het ethische en verantwoorde gebruik van AI binnen jouw organisatie? Neem dan contact op met onze creatieve en betrouwbare professionals via info@cuccibu.nl of +31 (0) 85 303 2984.
Reduce Risk, Create Value!